
What Organisations Need to Do Now
Artificial intelligence is about to change the way organisations manage data assets, and not in a marginal way. Over the next few years, AI will force businesses to rethink the value, structure, governance and operational management of data across the enterprise.

For years, most organisations have spoken about data as a strategic asset. In practice, however, many still manage it inconsistently. Data is often spread across multiple platforms, owned ambiguously, defined differently by different teams, and governed with varying levels of discipline. That model is becoming untenable.
AI changes the equation because it depends on data in a much more immediate and demanding way. Traditional reporting environments can often absorb poor definitions, stale records or inconsistent metadata without immediate failure. AI cannot. Whether it is generative AI, machine learning, intelligent automation or retrieval-based systems, the outputs are only as reliable as the data foundations beneath them. As AI adoption accelerates, organisations will need to manage data assets with much greater precision, accountability and rigour.
Data assets will move from passive repositories to active production inputs
One of the biggest shifts ahead is that data assets will no longer be treated simply as repositories for reporting, compliance or historical analysis. They will become live production inputs into systems that generate insights, automate decisions, support customer engagement and shape operational outcomes.
That has significant implications. When data is only used for retrospective reporting, defects can sometimes be tolerated for longer than they should be. When the same data is fed into AI systems, those weaknesses are amplified. Poor quality, missing context, inconsistent definitions and unclear lineage do not stay hidden for long. They surface as incorrect recommendations, misleading outputs, flawed automation and reduced trust.
This means organisations will increasingly need to treat important datasets as managed products rather than technical artefacts. Data assets will need clear ownership, service expectations, quality controls and usage rules. In effect, AI will accelerate the shift towards a more disciplined data product operating model.
Governance will become more important, not less
There is a common assumption that AI is primarily a model challenge. In reality, it is just as much a data challenge. The near-term future of AI governance will be heavily shaped by how well organisations govern the data feeding those systems.
That means the management of data assets will need to become more explicit in several areas. Organisations will need to know where data comes from, how it has been transformed, what permissions apply to it, whether it is suitable for a given AI use case, and how sensitive it is from a legal, regulatory or ethical perspective.
This is where many current environments are still immature. Metadata is incomplete. Lineage is partial. Business definitions are fragmented. Access rules are uneven. AI will expose all of these issues very quickly.
In practical terms, stronger data governance will become a prerequisite for safe and scalable AI. Businesses will need tighter control over provenance, lineage, classification, retention, transformation logic and approved reuse. The governance function itself will also need to evolve, moving from periodic oversight into something more embedded, operational and continuous.
Metadata will become strategic infrastructure
If AI has a hidden dependency, it is metadata.
In the near future, metadata will become one of the most important strategic capabilities in data asset management. It is the layer that tells both humans and machines what a dataset means, who owns it, how current it is, how reliable it is, what can be done with it and what constraints apply.
Without strong metadata, AI systems operate with insufficient context. They may retrieve data that is technically accessible but semantically inappropriate. They may use information that is outdated, sensitive or poorly governed. They may generate outputs that appear credible while relying on sources that should never have been used in the first place.
For this reason, organisations should expect increased investment in data catalogues, business glossaries, lineage tooling, semantic layers and policy-driven metadata management. Some will go further and adopt knowledge graph approaches to connect business concepts, data entities, policies and controls in a way that supports automation at scale.
The point is simple: in an AI-enabled enterprise, metadata is no longer administrative overhead. It is operational infrastructure.
Data quality will become a continuous discipline
AI will also change how organisations think about data quality.
Historically, many data quality programs have focused on periodic cleansing exercises, exception reporting and project-based remediation. That will not be sufficient in the AI era. AI systems are dynamic, iterative and often embedded in business processes. They require a more continuous model of quality assurance.
This includes not only traditional issues such as completeness, accuracy and consistency, but also more complex concerns such as timeliness, contextual relevance, label integrity, semantic drift and hidden bias in source data. Organisations will need to move from static quality checks to active monitoring and continuous validation.
That means future-ready data asset management will include ongoing quality scoring, anomaly detection, schema change monitoring, lineage break detection and feedback loops from AI performance into source data stewardship. If an AI assistant repeatedly produces poor answers because a core dataset is stale or ambiguously defined, that is not simply an AI issue. It is a data asset management issue.
Stewardship will become cross-functional
Another important shift is organisational. Managing data assets for AI cannot sit solely with a central data team. The implications of AI span legal, risk, security, operations, compliance, architecture and business leadership. That means stewardship will need to become much more cross-functional.
As data assets are reused across analytics, automation and AI-driven interactions, the stakes increase. A dataset that once seemed low-risk in a reporting context may become highly sensitive when exposed through a customer-facing assistant or used in automated decision support. Organisations will therefore need much clearer accountability around who can approve data for AI use, who owns quality thresholds, who certifies suitability and who intervenes when risk tolerance is exceeded.
This is one of the most overlooked preparation tasks. Many organisations are investing in AI capability without sufficiently redesigning the operating model for data accountability. That gap will become increasingly visible.
How organisations should prepare now
The good news is that the required preparation is not mysterious. It is disciplined, achievable and largely grounded in good data management practice, albeit with a sharper sense of urgency.
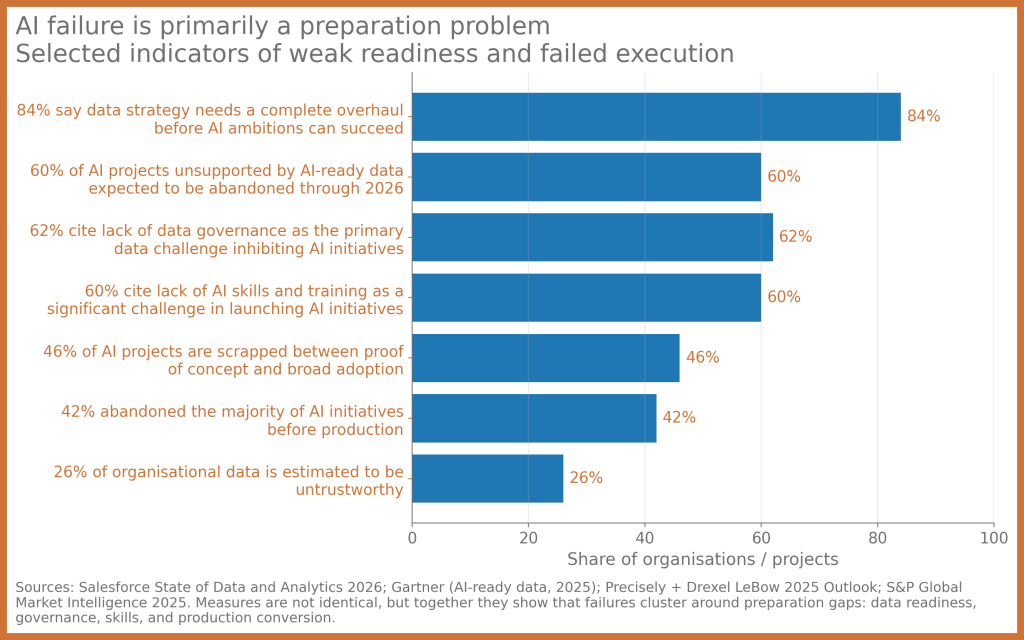
The first priority is to identify which data assets are likely to be used in AI initiatives over the next 12 to 24 months. That includes customer data, operational data, knowledge repositories, document stores, reference data and transactional assets that may feed models, copilots, recommendation engines or intelligent workflows. Once identified, these assets should be classified according to business criticality, sensitivity, provenance and fitness for reuse.
The second priority is to strengthen the minimum metadata and governance baseline. Each important data asset should have a clearly assigned owner, a consistent business definition, an understood lineage, an access classification and a refresh expectation. Where that information does not exist, it needs to be created.
The third priority is to modernise data quality management. Rather than relying on quarterly fixes or project-by-project remediation, organisations should establish continuous monitoring and escalation processes for the datasets most likely to support AI use cases.
The fourth priority is to integrate AI governance and data governance. These should not be separate conversations. The same governance structures that oversee sensitive data use should also be involved in approving AI applications, particularly where regulated or customer-impacting data is involved.
Finally, organisations should start building towards greater automation in policy enforcement, metadata management and lineage capture. Manual governance will not scale in an environment where AI systems are constantly interacting with enterprise data. The firms that prepare now will be in a stronger position to adopt AI safely and effectively.
The strategic opportunity
It is easy to view this as a compliance exercise or a governance burden. That would be a mistake.
The organisations that respond well to AI’s impact on data asset management will not merely reduce risk. They will create competitive advantage. They will move faster because their data is easier to trust. They will deploy AI more confidently because their controls are stronger. They will spend less time resolving ambiguity and more time generating business value.
In that sense, AI is not just putting pressure on data management. It is creating an opportunity to finally treat data with the strategic discipline it has long deserved.
Final thought
In the near future, AI will not make data asset management less important. It will make it central.
Organisations that continue to treat data as a loosely governed by-product will struggle to scale AI beyond isolated pilots. Those that invest now in governance, metadata, quality, stewardship and operational accountability will be far better placed to convert AI from hype into measurable enterprise value.
The real question is not whether AI will change the management of data assets. It already is. The real question is whether organisations are preparing quickly enough.
